📌 Key Takeaways
Operations break at hand-offs, not inside tools—where data moves between systems or responsibility shifts between teams.
For mid-market operations managers juggling fragmented systems and recurring hand-off failures, these takeaways clarify how to stabilize your most critical transitions without replacing your entire stack:
• Scope the highest-impact fragility first: Target the hand-off that fails most often with the highest business cost—frequent escalations, repeated rework, or SLA breaches—rather than the flashiest problem.
• Data contracts eliminate semantic drift: Explicitly define what each field means, who owns it, what validation it requires, and what happens on failure before you automate anything.
• RACI clarifies decision rights and shortens escalation paths: Assign Responsible, Accountable, Consulted, and Informed roles to prevent the “who should decide this?” paralysis that stalls critical fixes.
• Build only what eliminates the failure mode: Automate the minimum connection that honors your data contract and preserves existing security and quality gates—resist scope creep that delays measurement.
• Measure three auditable metrics in 30 days: Track Time-to-Value, rework rate, and SLA adherence with baseline comparisons that Finance and Compliance will trust enough to fund expansion.
Fix one fragile crossing in 30 days with clear contracts, explicit ownership, and auditable proof—then replicate that win across your operation.
When operations teams juggle multiple systems, the breaking points aren’t random. They cluster at hand-offs—those moments when data moves from one tool to another, or when responsibility shifts from one team to the next. The cost shows up as rework, missed SLAs, and hours spent reconciling what should have matched from the start.
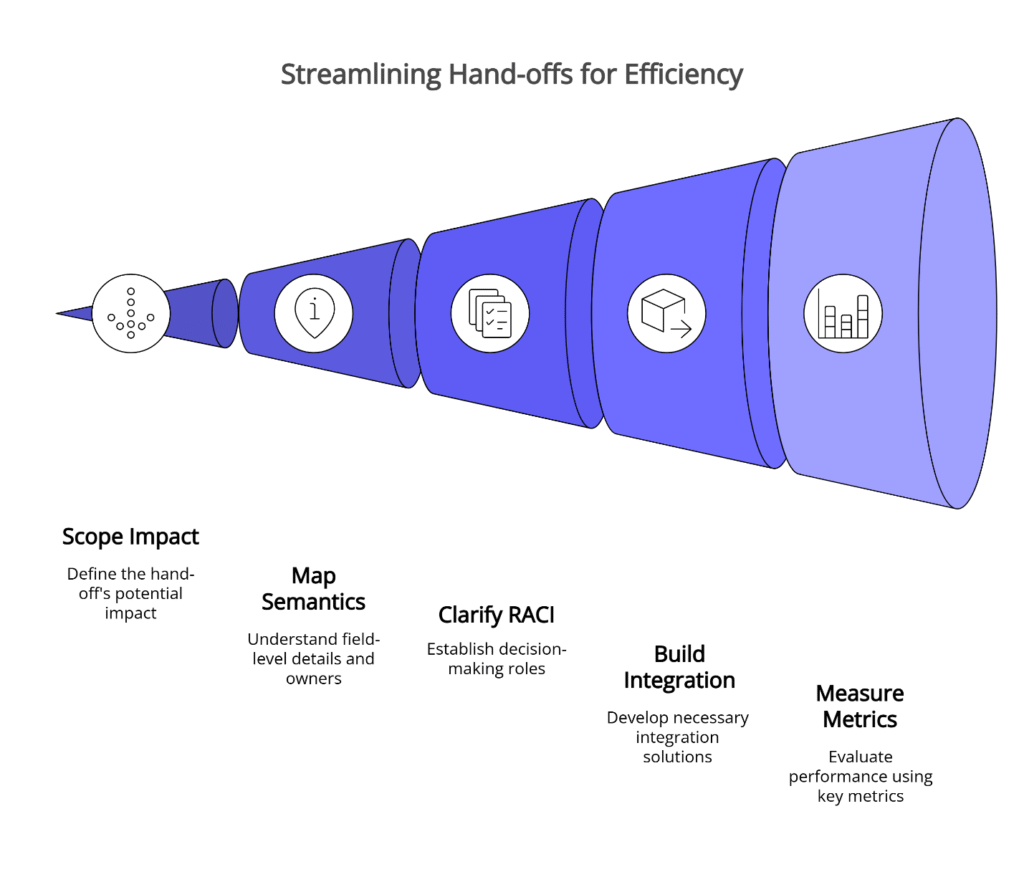
“One flow” means hardening your most fragile hand-off first. A 30-day pilot gives you a controlled way to prove value while keeping security and quality gates intact. The playbook has five steps: Scope the highest-impact hand-off, Map the field-level semantics and owners, clarify RACI decision rights, Build the minimum-necessary integration, and Measure three auditable metrics—Time-to-Value, Rework rate, and SLA adherence. This approach reduces change risk, surfaces governance issues early, and creates a template for scaling wins across your operation.
Why Hand-Offs Break (and How One Flow Fixes Them)
Hand-offs fail when teams re-key data across fragmented tools, lack clear decision rights, and automate before agreeing on field-level meaning. One flow fixes this by defining data contracts, assigning RACI roles with change gates, and building the minimum integration that preserves security and quality checks while eliminating duplicate entry.
Most mid-market operations run on a patchwork of specialized tools. Marketing automation feeds the CRM. The CRM triggers ticketing. Ticketing updates billing. Each transition represents a potential failure point.
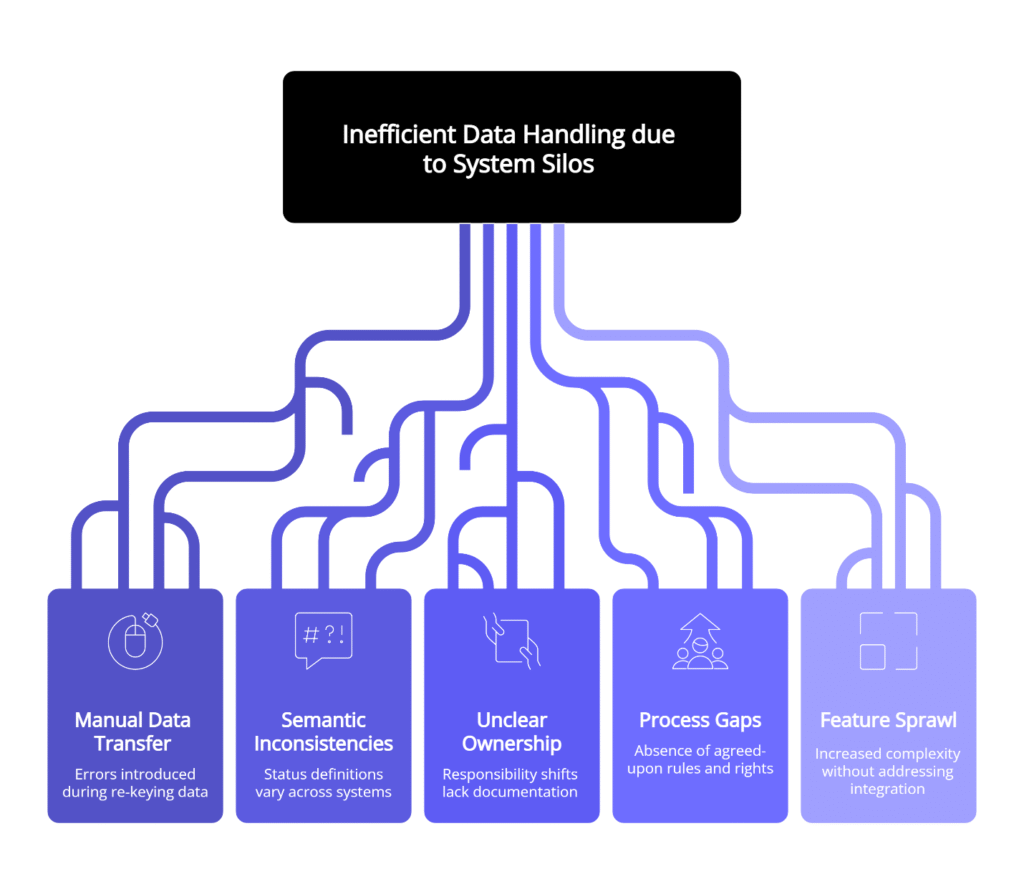
The hidden cost accumulates in predictable ways. Teams re-key data between systems, introducing errors with each manual transfer. Status gets lost in translation when one system’s “complete” doesn’t match another’s definition. Ownership becomes murky when responsibility shifts without clear documentation. What looks like a technology problem often masks a process gap—the absence of agreed-upon semantics, validation rules, and decision rights.
Feature sprawl makes this worse. When organizations try to solve hand-off problems by adding more capabilities to existing tools, they increase complexity without addressing the underlying integration debt. A platform may promise end-to-end visibility, but if teams still maintain separate spreadsheets to “fill the gaps,” the fragmentation persists beneath a veneer of consolidation.
The right-fit approach starts differently. Rather than attempting to unify everything under one platform, successful operations identify their most fragile hand-off—the one that breaks most often with the highest business impact—and standardize just that transition first.
The Hidden Cost of Re-Keying and Tool Fragmentation
Consider a typical scenario: the operations manager receives an urgent request from Finance to explain why last quarter’s fulfillment metrics don’t align with what Sales reported. The answer sits somewhere between three systems, but extracting it requires downloading CSVs, normalizing field names, and manually matching records that should have connected automatically.
This isn’t a tool failure. The individual systems work as designed. The breakdown happens at the boundary—where one system’s “customer ID” doesn’t match another’s “account number,” or where timestamp formats differ just enough to prevent automated reconciliation.
Re-keying creates inconsistency, delays, and silent errors. Each copy introduces a second “truth,” and every second truth invites rework. Fragmented tools multiply the problem: the ticketing system tracks status, a form app holds intake details, and a spreadsheet becomes the de facto data model—until nothing matches.
Complex stacks don’t fail only at the edges. They fail at hand-offs where semantics diverge. When “customer_id” means one thing to Support and another to Billing, automation amplifies confusion instead of reducing it. Organizations attempting to address this through feature additions often discover that complexity grows faster than capability. Each new integration point multiplies the potential for mismatch. According to research from the National Institute of Standards and Technology on interoperability challenges, inadequate interoperability costs U.S. industries billions annually, with much of that waste concentrated at system boundaries where semantics diverge.
The pattern repeats across industries. Healthcare systems struggle to exchange patient records between facilities. Supply chains lose visibility when freight data doesn’t align with inventory systems. Financial services firms reconcile transactions manually because core banking platforms speak different dialects than payment processors.
Feature Sprawl vs. Right-Fit Integration
The instinct to solve integration problems by adding features follows a familiar logic: if the current tool doesn’t connect well to the next step in the workflow, perhaps upgrading to the “enterprise” tier—or switching to an all-in-one platform—will eliminate the gaps.
This approach can work when the underlying processes are stable and well-documented. But when hand-off failures stem from unclear ownership, inconsistent data definitions, or missing validation rules, adding features simply automates the confusion. Adding more features rarely rescues a broken flow. Right-fit integration means choosing the smallest change that eliminates a specific failure mode—usually the most fragile hand-off.
A right-fit integration strategy inverts this sequence. Define the data contract first—what fields must transfer, who owns them, what validation they require, and what constitutes success. Then build the minimal connection needed to honor that contract. This approach surfaces governance gaps early, when they’re cheapest to fix, and creates reusable patterns for subsequent integrations.
The distinction matters because mid-market operations rarely have the luxury of comprehensive system overhauls. Teams need wins that deliver measurable value within budget cycles that Finance will approve. A 30-day pilot targeting one critical hand-off provides that foundation.
The 30-Day Pilot Playbook: Scope → Map → RACI → Build → Measure
Fixing everything at once creates risk that kills momentum. The pilot approach reduces that risk by focusing energy on a single, high-impact hand-off while preserving the governance structures that protect production operations.
This playbook provides a structured path from selection through measurement, with clear decision points and artifacts that communicate progress to stakeholders across Operations, IT, and Finance.
Scope: Pick the Most Fragile Hand-Off
Not all hand-offs deserve equal attention. Some transitions happen infrequently with minimal consequence when they fail. Others occur dozens of times daily, and each failure cascades into rework that consumes hours of skilled labor.
The selection tool is a simple two-by-two grid: frequency on one axis, business impact on the other. Frequency measures how often the hand-off occurs—daily, hourly, or with every transaction. Impact assesses what happens when it fails: Does it delay revenue recognition? Trigger SLA breaches? Force manual intervention by senior staff?
Plot your candidate hand-offs on this grid. The upper-right quadrant—high frequency, high impact—contains your pilot targets. Within that quadrant, prioritize the hand-off that most clearly demonstrates one of these patterns:
- Frequent escalations to management for resolution
- Repeated requests from Finance or Compliance for data reconciliation
- Known workarounds where teams maintain parallel tracking systems
- High rework rates that consume significant hours each week
Select the hand-off that fails often and hurts the most when it does. Common signals include frequent re-opens, repeated copy-paste, status ping-pong, and “where is this now?” questions from stakeholders. Avoid the “flashiest” candidate. Choose the one with ready access to owners, stable inputs, and a clear after-state you can measure within 30 days.
Document the selection rationale. This becomes the baseline narrative for demonstrating ROI: “We chose the order-to-fulfillment hand-off because it occurs 200 times per week, each failure delays shipment by an average of 4 hours, and the rework costs approximately 15 staff hours weekly.”
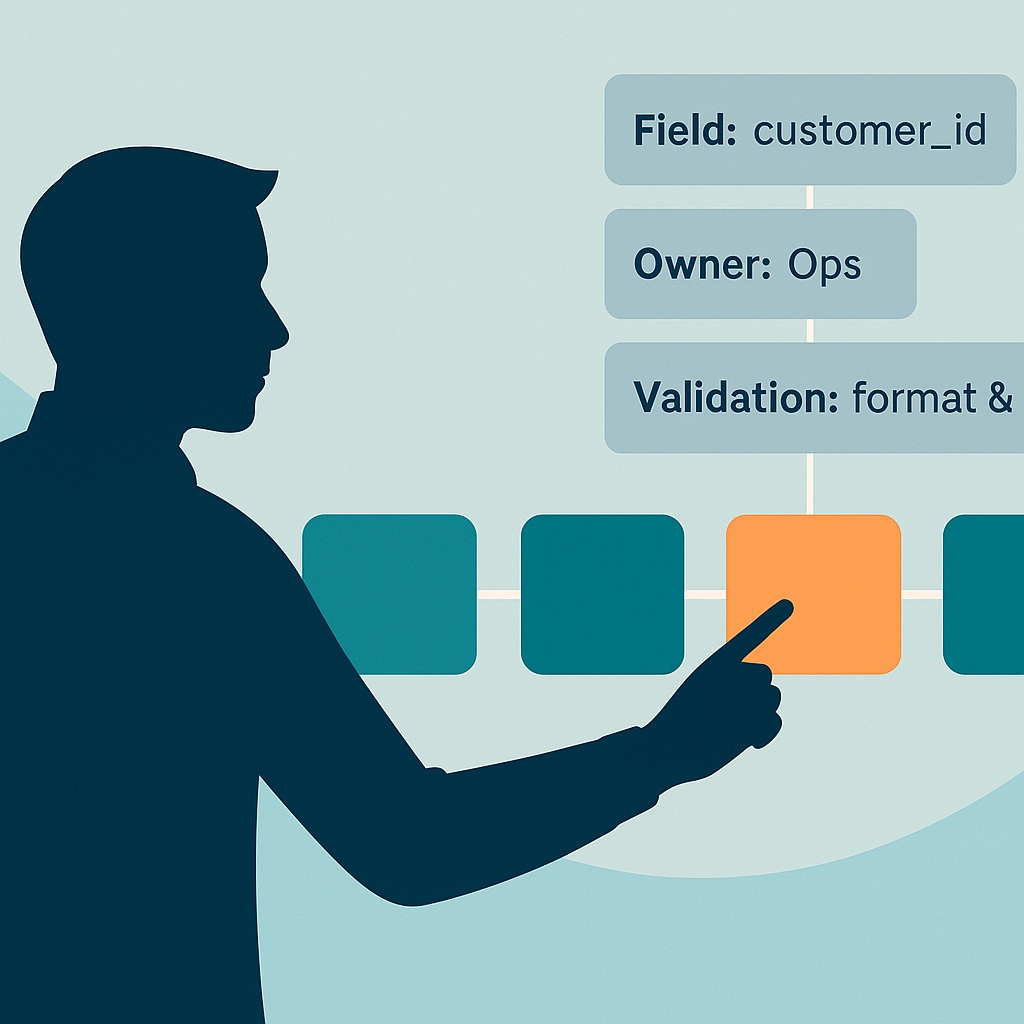
Map: Field-Level Semantics and Data Contracts
Once the target hand-off is selected, the next step maps what actually moves between systems. This isn’t a technical exercise delegated entirely to IT. Operations owns the semantic clarity—defining what each field means, how it’s validated, and what happens when data quality fails to meet thresholds.
Start by documenting the current state. What fields does the upstream system provide? What does the downstream system require? Where do naming conventions diverge? A common pattern: the CRM tracks “Company Name” while the ERP system expects “Legal Entity Name,” and nobody documented that these don’t always match.
Map every field that crosses the boundary. Define name, type, allowed values, owner, validation rule, and the source of truth. Mark optional versus required. Decide what happens on conflict.
For each field that crosses the boundary, define:
- Source: Which system provides this data, and which specific field or API endpoint?
- Owner: Who is responsible for data quality at the source? Who validates it at the destination?
- Validation rules: What makes this data “good enough” to use? Formats, allowable ranges, required dependencies.
- Failure behavior: When validation fails, who gets notified, and what’s the recovery path?
This mapping exercise often reveals why hand-offs fail. The upstream system may not enforce data quality rules that the downstream system depends on. Ownership may be ambiguous—everyone assumes someone else is checking for duplicates. Required fields may be optional in practice, creating gaps that surface only after data has moved.
Create a data contract document that both teams sign off on. This isn’t bureaucracy for its own sake. It’s the foundation for automated validation and the basis for measuring improvement. Without it, the pilot will reproduce the same ambiguities that caused the original failures. A data contract removes guesswork, eliminates free-text drift, and lets you create validation that prevents bad entries from moving downstream.
RACI: Decision Rights and Change Controls
Technical integration succeeds or fails based on clarity about who owns what. The RACI model—Responsible, Accountable, Consulted, Informed—provides a lightweight structure for documenting decision rights without creating excessive overhead.
For the pilot hand-off, assign RACI roles to each major decision and action:
- Data quality at source: Who is Responsible for ensuring fields meet validation rules before hand-off? Who is Accountable (final decision authority)? Who must be Consulted before changes? Who must be Informed when issues arise?
- Integration logic: Who is Responsible for building and maintaining the connection? Accountable for approving changes? Consulted on requirements? Informed of deployments?
- Incident response: Who is Responsible for investigating failures? Accountable for authorizing rollbacks? Consulted on permanent fixes? Informed of post-mortems?
The value isn’t the acronym. The value comes from preventing the pattern where everyone thinks someone else is handling critical tasks, or where multiple people make conflicting decisions about the same issue. Role clarity reduces stalls and stabilizes cycle time. When “who decides?” is explicit, escalations shorten and weekend “side fixes” fade.
When teams disagree about a field definition or validation rule, use the data contract to settle it. Assign a field owner with authority to make the final call. If a value is unknown or disputed, reject the entry with a clear message or accept it with a flag that prompts a defined follow-up. This conflict resolution mechanism prevents deadlock and keeps the pilot moving forward.
Change controls deserve specific attention in a pilot. Production systems require gates—approval processes, testing requirements, rollback procedures—that protect stability. The pilot should implement scaled versions of those gates rather than bypassing them entirely. Define what “approved for pilot” means: What testing is required? Who signs off? What’s the rollback trigger?
This discipline prevents the scenario where a successful pilot can’t transition to production because it never honored the governance requirements that production systems must follow.
Build: Minimum-Necessary Integration with Gates Intact
The technical implementation should deliver the smallest possible working integration that honors the data contract and RACI model. Avoid the temptation to add “just one more field” or “handle this edge case while we’re at it.” Every expansion increases scope and delays measurement.
Automate only the crossing. Keep the fewest moving parts that eliminate re-keying and respect the agreed data contract. Preserve existing security and quality checks; don’t bypass them for speed.
For most mid-market operations, the integration follows a four-step pattern:
- Trigger: A single upstream event initiates the hand-off (e.g., “Intake submitted” or “Order approved”)
- Transform: Apply deterministic, field-level mapping that matches the data contract—normalize formats, map enumerations, trim whitespace
- Write: Perform an idempotent create or update operation in the downstream system to ensure repeated executions don’t create duplicates
- Log: Maintain a versioned record of what moved, when, and by whom or what process, enabling audit trails and root-cause analysis
The choice of implementation approach depends on your existing infrastructure, the systems involved, and the latency requirements. A hand-off that needs near-real-time sync requires different architecture than one that can tolerate daily batches.
Infrastructure considerations often make or break pilot success. Organizations building these integrations frequently discover that their underlying cloud infrastructure—the compute instances, networking configurations, and deployment environments—lacks the stability or documentation needed to support reliable system-to-system communication. When teams struggle with infrastructure drift, manual configuration updates, or undocumented dependencies between environments, integration pilots inherit those weaknesses.
This is where standardized, well-documented infrastructure patterns become critical. Gigabits Cloud provides pre-configured cloud images and deployment frameworks specifically designed to support reliable operations workflows. Rather than troubleshooting inconsistent base configurations during a time-sensitive pilot, teams can deploy from validated images that include the necessary middleware, logging, and monitoring capabilities already in place.
Regardless of implementation approach, preserve the security and quality gates that govern production systems. If production deployments require code review, the pilot does too—just with a tighter review scope. If data changes require approval from a data steward, that checkpoint remains active. If the audit trail requires logging who touched what when, implement that logging from day one. No unmanaged scripts—version everything with audit trails. Maintain pre-approved data scope with a risk register for exceptions. Define a rollback plan before the first production test.
These gates aren’t obstacles. They’re the reason Finance and Compliance will trust your results enough to fund expansion. A pilot that “works” but can’t scale because it bypassed governance creates technical debt instead of demonstrable progress.
Measure: Baseline Plus Three Auditable Metrics
Before the pilot goes live, capture baseline performance for three metrics that Finance and Operations both understand:
Time-to-Value (TTV): How long does it take from the moment data enters the upstream system until the downstream system can act on it? For an order-to-fulfillment hand-off, this might be “time from order entry to fulfillment queue ready.” Measure in hours or days, depending on your operation’s cadence.
Rework rate: What percentage of items crossing the hand-off require manual intervention or correction? This includes incomplete data that forces staff to look up missing information, duplicate entries that must be reconciled, or validation failures that require upstream fixes.
SLA adherence: What percentage of items complete the full journey within the agreed-upon timeline? If your fulfillment SLA promises 24-hour processing, this metric tracks how often the hand-off supports that promise versus how often delays push work past the deadline.
Capture a meaningful sample size—at least two weeks of activity, more if the hand-off doesn’t occur frequently—before the pilot begins. Assign ownership for each metric. Who measures it? How often? Who reviews the results and escalates issues?
Run the pilot for 30 days, then measure again. The goal isn’t perfection. The goal is directional improvement that’s large enough to matter: TTV reduced by 30%, rework rate cut in half, SLA adherence increased from 70% to 90%. These are the numbers that justify expanding the approach to additional hand-offs.
For early pilots, small absolute changes can matter if they’re consistent. Favor stability and clarity over “heroic” numbers. Pilots should be boring and repeatable—predictable improvements that can be replicated across other hand-offs without drama or exceptional effort.
Document the measurement methodology so that subsequent pilots can replicate it. This consistency allows you to compare results across different hand-offs and build confidence that the framework itself—not just luck on one specific integration—delivers value.
Week-by-Week Pilot Execution
Breaking the 30-day pilot into weekly milestones helps teams maintain momentum and provides natural checkpoints for stakeholder updates.
Week 0 (Preparation)
- Select the target hand-off using the frequency-times-impact grid
- Write a one-sentence scope statement defining trigger and outcome
- Secure access to system owners in both upstream and downstream teams
- Draft the baseline measurement plan for TTV, rework rate, and SLA adherence
Week 1 (Map & RACI)
- Build the complete field dictionary with owners, types, and validation rules
- Define transformation rules including enumeration mapping, trimming, and normalization logic
- Confirm error behavior: reject with message versus accept with flag
- Finalize the RACI table covering data quality, integration logic, and incident response
- Document change gates with approval criteria and testing requirements
Week 2 (Build)
- Implement the four-step pattern: Trigger → Transform → Write → Log
- Add version control for all integration artifacts
- Validate end-to-end flow in a safe test environment using real example data
- Prepare runbook entries covering common failure modes
- Create owner lookup table with paging contact information
Week 3 (Pilot Live)
- Go live for a limited slice of production traffic
- Track exceptions using the defined paging discipline
- Maintain status update cadence for stakeholders
- Protect governance controls—do not bypass gates for speed
- Log all integration activity for post-pilot analysis
Week 4 (Measure & Decide)
- Compare baseline metrics with pilot results: TTV, rework rate, SLA adherence
- Conduct a structured post-mortem focused on reusable patterns
- Add new integration targets to the backlog based on lessons learned
- Make expansion decision: scale to full production, hold for refinement, or retire approach
Governance Without Drag: Keep Security and Quality Gates Intact
Mid-market operations face a constant tension between moving fast and maintaining control. The pilot framework resolves this tension by implementing governance that protects what matters while avoiding bureaucracy that doesn’t.
Risk Register and Pre-Approved Data Scope
Before the pilot begins, create a concise risk register that documents potential failure modes and mitigation strategies. This doesn’t need to be exhaustive. Focus on the risks that would cause stakeholders to halt the pilot or refuse to scale it:
- Data leakage: What happens if the integration accidentally exposes sensitive information? Mitigation: Pre-approve the exact fields that cross the boundary and implement field-level access controls.
- System instability: Could the integration crash either system or degrade performance? Mitigation: Set rate limits, implement circuit breakers, and define rollback triggers.
- Compliance violations: Does the hand-off involve regulated data that requires audit trails or consent tracking? Mitigation: Document compliance requirements and validate them before launch.
The risk register serves two purposes. It forces the team to think through failure scenarios before they occur. And it provides Finance and Compliance with evidence that the pilot isn’t a reckless experiment—it’s a controlled test with defined boundaries.
Pre-approved data scope matters because scope creep kills pilots. When teams discover additional fields they “might as well transfer,” the integration grows more complex, testing takes longer, and the 30-day timeline slips. Worse, each new field may carry different security or compliance requirements that weren’t in the original approval.
Lock the field list before development begins. If new requirements emerge during the pilot, document them as inputs for the next iteration rather than expanding the current scope. Agreeing on what cannot move is as important as agreeing on what must.
Versioning and Audit Trail for the Pilot
Production integrations require change tracking: who modified what, when, and why. Pilots should honor this discipline even though they’re temporary.
Implement version control for integration logic. Whether the connection is a script, a workflow configuration, or a middleware setup, treat it as code that must be versioned and reviewed. This serves immediate practical needs—when something breaks, you can roll back to the last working version. It also creates documentation for the post-pilot review, showing exactly what worked and what didn’t.
Every artifact—field mapping, transformation logic, runbook—should be versioned. Integration actions should be logged with enough context to reconstruct events. This protects the pilot, satisfies auditors, and speeds root-cause analysis when something behaves oddly.
Maintain an audit trail of data movement during the pilot. Log when batches run, how many records transfer, which records fail validation, and who intervenes manually. This visibility pays off in multiple ways. When stakeholders ask “is it working?” you have objective evidence. When planning the transition to production, you know which edge cases occur frequently enough to deserve automated handling. When Finance asks whether the improvement is real, you can show before-and-after samples.
The audit trail doesn’t need enterprise-grade sophistication for a 30-day pilot. A structured log file or a simple database table that captures timestamp, record ID, status, and any error messages provides sufficient visibility for most mid-market operations. Keep a simple “pilot change note” that records the reason for any modification, its date, and the acceptance check it passed. Consistency beats complexity.
Runbooks That Prevent Regression
Successful pilots can fail to scale if they depend on heroic individual effort. The operations manager who “just knows” how to fix common issues becomes a bottleneck. The integration that requires manual restarts every few days never achieves production reliability.
Runbooks—documented procedures for common tasks and failure scenarios—transform ad hoc problem-solving into repeatable operational discipline.
Owner Lookup Tables and Paging Discipline
When the integration encounters an issue, the first challenge is often figuring out who to notify. The marketing automation specialist? The CRM administrator? The middleware vendor’s support team? Delays in reaching the right person compound the impact of whatever technical issue triggered the alert.
Create a simple owner lookup table that maps issue categories to responsible individuals:
- Data quality issues: Who owns validation at the source system?
- Connectivity failures: Who manages the network path between systems?
- Downstream processing errors: Who troubleshoots the receiving system?
- Business rule questions: Who has authority to interpret edge cases?
For each owner, document paging discipline: How should they be contacted? What’s the escalation path if they’re unavailable? What information should the page include? Consider maintaining a small set of pre-written response templates that reflect the data contract and flow states, reducing improvisation during incidents and ensuring consistency in how issues are communicated.
This discipline extends concepts familiar from incident response frameworks. The NIST Computer Security Incident Handling Guide emphasizes that first-hour behaviors—how quickly the right people are engaged with the right information—dominate variance in incident outcomes. The same principle applies to integration failures. The team that can identify and escalate issues within minutes achieves dramatically better outcomes than the team where problems languish for hours before someone realizes they need attention. Early actions dominate outcomes. Clear first-hour expectations keep variance low and confidence high.
For operations teams managing multiple system integrations, establishing standardized runbooks becomes exponentially more valuable. Teams working with ready-to-deploy cloud images benefit from having consistent base configurations across environments, which simplifies troubleshooting by reducing the “it works on my machine” problem. When every deployment environment starts from a known, documented state, runbooks can reference specific file paths, service names, and configuration patterns without requiring constant updates for environmental drift.
Status Update Cadence That Calms Stakeholders
During the 30-day pilot, stakeholders—particularly those who approved budget and political capital for the experiment—will want visibility into progress without becoming bottlenecks themselves. The status update cadence needs to provide sufficient transparency while avoiding the overhead of constant reporting.
A proven pattern: brief weekly summaries that follow a consistent format:
- What shipped this week: Specific integration milestones completed
- What’s blocked or at risk: Issues that require stakeholder intervention or decisions
- Key metrics update: Current TTV, rework rate, and SLA adherence numbers compared to baseline
- Next week’s focus: Specific deliverables planned
Keep these updates short—under 300 words. Each update should state current state, next step, and owner—no drama, no jargon. The goal is to make it easy for busy executives to stay informed, not to overwhelm them with technical detail. Predictable communication prevents executive escalations that can derail disciplined fixes.
For issues that require immediate stakeholder attention—a critical bug, a scope clarification, a dependency on another team—use a separate escalation channel rather than waiting for the weekly update. But reserve that channel for genuine urgency to maintain its effectiveness.
This status discipline serves the pilot in the moment and creates a template for future integrations. Teams that establish this communication rhythm during pilots find it easier to maintain visibility as the integration portfolio grows.
Scale the Wins: From One Pilot to One Flow
A successful pilot proves that the framework works for one specific hand-off. Converting that proof into organizational capability requires deliberate steps to capture learning, prioritize the next targets, and build internal consensus for continued investment.
Post-Mortems to Integration Backlog
At the pilot’s conclusion, conduct a structured retrospective that documents what worked, what didn’t, and what insights apply to future integrations:
- Technical patterns: Which integration approach (batch, webhook, shared view, middleware) proved most reliable? Were there data transformation patterns that can be reused?
- Governance insights: Did the risk register accurately predict failure modes? Were the security and quality gates sufficient, excessive, or in need of adjustment?
- Organizational dynamics: Which stakeholder communication patterns built trust? Where did coordination break down?
- Metric calibration: Were the chosen metrics (TTV, rework rate, SLA adherence) meaningful to stakeholders? Do they need refinement for subsequent pilots?
Run a concise post-mortem focused on what to reuse. Convert themes into backlog items: common field mismatches, recurring manual steps, and missing owner lookups. This retrospective feeds directly into the integration backlog—a prioritized list of hand-offs to address next, informed by the frequency-times-impact framework used to select the first pilot.
The backlog serves multiple purposes. It demonstrates to stakeholders that the organization is thinking systematically about integration debt rather than chasing one-off fixes. It helps Finance understand the potential cumulative ROI if the pilot approach scales across multiple hand-offs. It provides a roadmap that balances quick wins (additional high-frequency, high-impact targets) with strategic improvements (addressing cross-functional hand-offs that enable new capabilities).
Successful operations typically discover that the second and third pilots move faster than the first. Reusable patterns emerge. Teams become familiar with the documentation requirements. The RACI model gets easier to populate. This learning curve effect should be factored into business case projections—early pilots may take the full 30 days, while later pilots might compress into two or three weeks.
Phased Expansion Playbook and Contract Language
Scaling from pilot to portfolio requires deliberate expansion planning. Organizations that attempt to “roll out” the successful pilot to all remaining hand-offs simultaneously often discover that they’ve overwhelmed their change management capacity. Integration failures that were manageable in a controlled pilot become crises when they occur across multiple systems.
Scale in phases, not leaps. For each new hand-off, repeat the pattern: Scope → Map → RACI → Build → Measure. Keep contract language—internal agreements between teams—simple: what moves, who owns, which gates apply, how success is measured. Small pilots outperform big-bang bets. Each expansion should feel like a low-drama iteration, not a fire drill.
A phased expansion playbook typically includes:
Phase 1 (Months 1-3): Pilot the highest-impact hand-off. Baseline metrics, document patterns, train core team. Goal: Prove the framework works and build internal case studies.
Phase 2 (Months 4-6): Expand to 2-3 additional hand-offs that share similar patterns (same upstream or downstream systems, similar data contracts). Goal: Demonstrate reusability and refine templates.
Phase 3 (Months 7-12): Address hand-offs that require new integration patterns or cross additional organizational boundaries. Goal: Build comprehensive capability and formalize governance.
This phased approach aligns with how mid-market operations typically secure funding. Initial pilots often run on discretionary budget or reallocated staff time. Expansion phases require formal budget approval, which is easier to obtain when early results demonstrate ROI.
Infrastructure consistency becomes critical during expansion. Teams scaling from one pilot integration to a portfolio of five or ten quickly discover that environmental differences—variations in OS versions, middleware configurations, security policies, or network setups—consume disproportionate troubleshooting time. Each new integration shouldn’t require re-solving infrastructure problems that the previous pilot already addressed.
Organizations managing multiple integration pilots benefit from standardized deployment foundations. Gigabits Cloud’s approach—providing pre-configured, tested images for common cloud scenarios—directly addresses this scaling challenge. Teams can deploy consistent environments for each new pilot without rebuilding infrastructure from scratch, allowing them to focus effort on the business logic and data contracts specific to each hand-off rather than wrestling with base system configuration.
Contract language for vendor-supported integrations deserves specific attention. When the hand-off involves third-party platforms or middleware, expansion beyond the pilot may trigger additional licensing costs or require upgraded service tiers. Negotiate these terms before the pilot begins to avoid surprises that delay scaling. Specifically, clarify:
- Licensing model for additional integrations or higher transaction volumes
- Support commitments for production deployment versus pilot testing
- Data residency and compliance requirements if the integration handles regulated information
- Service-level agreements for integration uptime and vendor response time
Organizations that discover these constraints only after a successful pilot often face months of contract negotiation that erode momentum and stakeholder confidence.
Common Misconceptions About Integration Pilots
Several widespread assumptions can undermine pilot success before teams even begin. Addressing these misconceptions early helps set realistic expectations and prevents costly detours.
“We need a data lake first.” Many teams believe they must first consolidate all operational data into a central repository before attempting any integration work. For a 30-day pilot targeting one specific hand-off, this is unnecessary and creates months of delay. A data contract at the boundary—defining exactly what crosses from one system to another—is sufficient to prove value. Build the lake later if comprehensive analytics justify it, but don’t let perfect data architecture prevent practical progress.
“If we automate it, problems go away.” Automation is powerful, but it multiplies whatever semantics you feed it. If upstream and downstream systems disagree about what “customer_tier” means, automating the hand-off will propagate that confusion faster and at greater scale. Define the data contract first, align on field meanings and validation rules, then automate. Code executes instructions; it doesn’t resolve ambiguity.
“RACI is red tape.” Teams often view formal role assignment as bureaucratic overhead that slows decision-making. In practice, RACI acts more like a stopwatch—it accelerates cycles by eliminating the “who should decide this?” paralysis that causes work to stall. Clear roles shorten escalation paths and make approvals predictable. The alternative—ad hoc coordination through meetings and email chains—consumes far more time than documenting responsibility once.
Deep Dive: Data Contracts, RACI, and “Minimum-Necessary” Integration
Understanding why these three elements matter helps teams execute pilots with confidence rather than treating them as compliance checkboxes.
Critical importance: Data contracts prevent semantic drift across tools. They enable validation that keeps bad entries from contaminating downstream systems. When everyone agrees that “product_tier” accepts only the values “basic,” “premium,” or “enterprise”—and the upstream form enforces this as a dropdown rather than free text—downstream reports become trustworthy without manual cleanup.
RACI clarifies who makes which decisions, avoiding stalls. When a field validation fails at 3 AM, the runbook should specify exactly who gets paged and who has authority to approve an emergency bypass. Without this clarity, incidents stretch from minutes to hours while people debate who should act.
A minimum-necessary build reduces risk and keeps governance review small and focused. Every additional field, every extra transformation rule, every new system touched expands the surface area for failure and lengthens the approval cycle. The pilot that moves only five critical fields can launch in weeks; the one that attempts comprehensive synchronization may never ship.
Real-world implications: With a contract and RACI in place, you can safely manage change. New fields, new values, or new tools pass through defined gates with known reviewers. Service quality improves because fewer surprises reach customers or internal users. Post-mortems become shorter and more actionable because the team knows who owned each decision and can trace exactly what happened.
When you’re ready to standardize your first critical hand-off, explore Gigabits Cloud’s documentation and deployment guides for infrastructure patterns that support reliable integration pilots—or contact our team to discuss how consistent cloud environments can accelerate your path from pilot to portfolio.
Resources
The following resources support implementation of the one-flow framework:
- Gigabits Cloud Documentation: Quick Start Guide – Foundational guidance for deploying reliable cloud infrastructure that supports system integration
- Gigabits Cloud: Ready-to-Deploy Solutions – Pre-configured cloud images designed for consistent, documented operational environments
- First Deployment Guide – Step-by-step implementation patterns for common cloud infrastructure scenarios
- AWS Marketplace: Gigabits Cloud Solutions – Validated infrastructure images available for immediate deployment
- Gigabits Cloud Support – Direct assistance for pilot scoping and implementation questions
Disclaimer: This article provides operational guidance and implementation frameworks. It does not constitute legal, security, compliance, or financial advice. Organizations should consult appropriate professionals before implementing changes to production systems or data handling practices.
Our Editorial Process
This framework synthesizes established operations management principles with contemporary integration patterns observed across mid-market organizations. We corroborate guidance with credible sources including government standards bodies and peer-reviewed research. Content undergoes plain-language review to ensure accessibility while maintaining technical accuracy.
About the Author
The Gigabits Cloud editorial team specializes in pragmatic operations frameworks and ready-to-deploy cloud infrastructure. With over 15 years of experience in IT operations, we focus on implementation patterns that deliver measurable value within realistic timeframes and budget constraints.






