
📌 Key Takeaways
Hand-rolled AMIs create invisible technical debt that surfaces as release delays, security fire drills, and audit friction.
- Configuration Drift Blocks Velocity: When every engineer builds images differently, production fleets diverge silently until a CVE or audit forces teams to manually verify which systems contain what—consuming hours that should be spent shipping features.
- Image-Based Patching Beats Instance Patching: Updating a baseline AMI once and propagating it through controlled rollout provides faster, more predictable vulnerability response than patching hundreds of instances individually with varying configurations.
- SBOM + Attestations = Reusable Evidence: A Software Bill of Materials cataloging every component plus cryptographic attestations transforms security approval from a repeated, manual verification process into a one-time review that satisfies multiple audits.
- AWS Marketplace Eliminates Procurement Friction: Private offers allow custom terms while consolidating billing through existing AWS accounts, cutting weeks from traditional vendor onboarding cycles.
- Standardization Enables Advanced Operations: Blue-green deployments, canary releases, and disaster recovery all become reliable when infrastructure homogeneity guarantees consistent instance behavior regardless of launch timing or location.
Baseline-driven infrastructure replaces firefighting with predictable execution.
Cloud operations teams, platform engineers, and DevOps leaders managing EC2 fleets will find this framework directly applicable here, preparing them for the detailed implementation guidance that follows.
An AMI on AWS (Amazon Machine Image) is a pre-built template that defines the operating system, configuration, and software for your EC2 instances, as documented in the official AWS user guide. Think of it as the master blueprint your infrastructure team uses every time you need to launch a new server. The problem many teams face is that hand-rolled or generic AMIs create drift across environments, leading to configuration variance, inconsistent patch levels, and recurring security fire drills.
A factory-standard AMI baseline changes this reality. Instead of maintaining multiple slightly different image builds across your accounts and regions, you adopt a single, vetted baseline that comes pre-hardened with security controls, packaged with Software Bill of Materials (SBOM) documentation, and accompanied by attestations that serve as an evidence package from day one. This standardized approach prevents the slow accumulation of configuration drift, enables image-based patch cadence for zero-day responses, and satisfies Security and Audit teams without requiring repeated ad-hoc evidence gathering for every release.
The practical difference shows up in your day-to-day work. When a critical vulnerability surfaces, your team updates the baseline AMI once, tests it in a controlled environment, and propagates the updated image across your fleet using your existing distribution patterns. Compare this to the chaos of manually patching hundreds of instances with varying configurations, each requiring individual verification. The baseline approach delivers faster, more predictable releases while significantly reducing the risk of configuration-related outages or audit findings.
Why a Factory-Standard AMI Wins
| Approach | Drift & Configuration Variance | CVE Exposure & Patch Cadence | Audit Readiness & Evidence Effort | Time to Deploy / Time to Approval |
|---|---|---|---|---|
| Hand-rolled / ad-hoc AMIs | Higher drift—each build introduces subtle differences across teams and environments | Less consistent—teams patch reactively with varying response times | More manual evidence collection for each release; findings require rework | Longer approvals due to missing or incomplete documentation |
| Generic base AMIs with manual hardening | Moderate drift—hardening steps vary by implementer and drift over time | Moderate consistency—requires manual tracking and coordination for patches | Evidence exists but scattered; audit teams request same info repeatedly | Variable delays while teams compile and validate hardening proof |
| Factory-standard AMI on AWS with bundled SBOM & attestations | Lower drift—single source of truth deployed consistently across environments | More predictable—image-based cadence with controlled rollout and rollback | Evidence package ready from day one; single review satisfies multiple audits | Faster approvals using pre-validated baseline and standard procurement terms |
Note: These comparisons reflect common patterns observed across different AMI management approaches. Actual results depend on specific implementation details, organizational practices, and existing infrastructure maturity.
Provided by Gigabits Cloud – AMI on AWS specialists.
Explore our hardened AMIs and zero-day response to see how this baseline approach fits into your existing workflows.
How a Standard AMI Changes Your Day-to-Day Releases
Picture a release night where everything that could go wrong does. Your team is two hours into deploying a critical update when Security flags a new CVE that affects the base OS layer. The vulnerability was disclosed that afternoon, and you need to patch before the deployment window closes. But here’s the problem: your production fleet runs on AMIs that three different engineers built over the past eighteen months, each with slightly different hardening steps, package versions, and configuration files.
One engineer tries patching an instance in staging, but the update breaks because the package manager was configured differently on that particular image. Another team member discovers that half the fleet is missing a security tool that should have been part of the standard build. By the time you manually verify which instances need which specific patches, it’s 3 AM and the deployment is postponed. The next morning, Audit sends an email asking for evidence that all production systems meet the organization’s security baseline. Nobody has a definitive answer because there isn’t a single baseline—just a collection of images that evolved organically over time.
This scenario repeats itself across infrastructure teams because hand-rolled AMIs accumulate technical debt in ways that aren’t visible until something breaks. A factory-standard AMI baseline eliminates this pattern entirely. When that same CVE alert arrives, your response is fundamentally different. You update the baseline AMI (for example, moving from baseline-2025.05.1 to baseline-2025.05.2)—the single, authoritative source that defines what “production-ready” means for your organization. You test the updated image in a lower environment, verify that your deployment automation works as expected, and then propagate the new AMI ID through your accounts using the same distribution mechanism you use for every other release.
The shift from firefighting to predictable releases happens because the baseline removes the variables that create uncertainty. Security knows exactly what controls are present because the SBOM and attestations document every component. Operations knows the image will behave consistently because it’s the same tested artifact in development, staging, and production. Audit has evidence ready before they ask for it because the documentation is part of the artifact itself, not something teams scramble to compile after the fact.
What Is an AMI on AWS? (Definition, Analogy, and Mental Model)
An Amazon Machine Image is essentially a snapshot of a complete server configuration, packaged in a format that AWS uses to launch EC2 instances. When you click “Launch Instance” in the AWS console or execute a deployment through your infrastructure-as-code tooling, you’re pointing to an AMI that contains the operating system kernel, system libraries, application runtime environments, and any pre-installed software packages. The AMI also includes block device mappings that define how storage volumes attach to the instance and permission settings that control who can use the image.
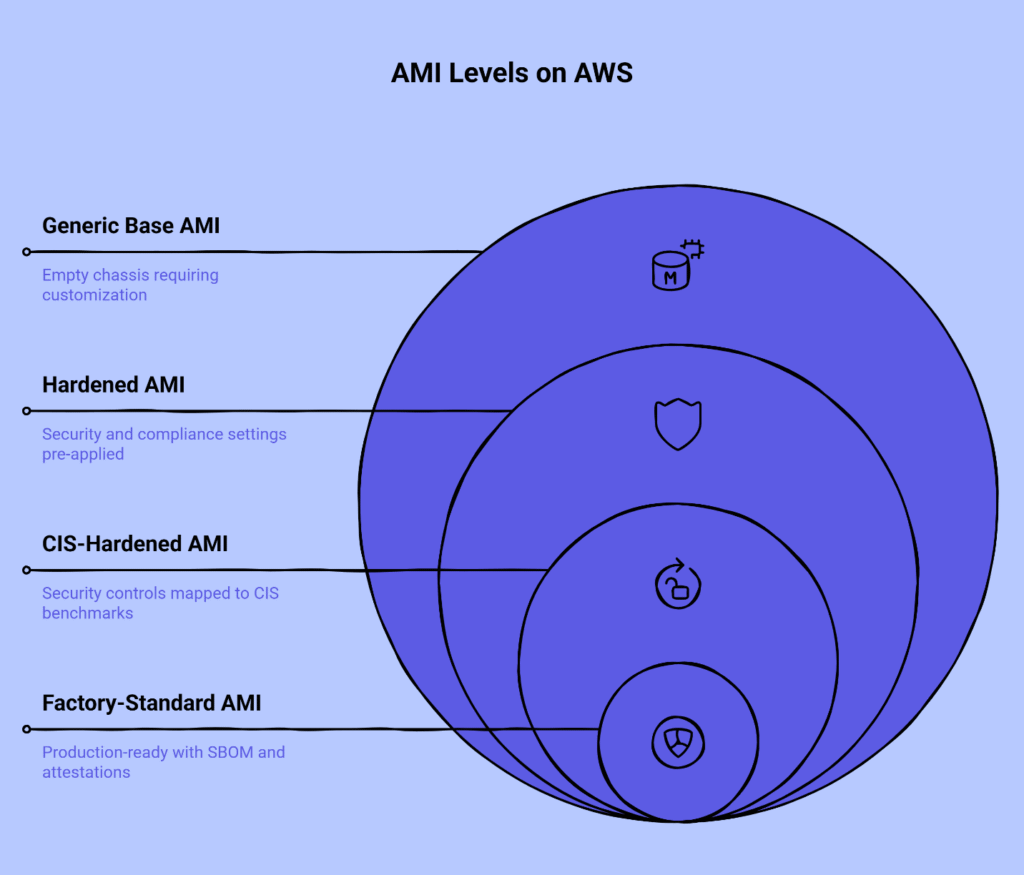
The most useful way to think about this is as a manufacturer-approved factory baseline for your vehicle fleet. When an enterprise standardizes on a specific truck model for deliveries, they don’t ask each regional manager to individually spec out and build custom trucks from parts. They order from the factory with a documented configuration that includes safety systems, standard equipment, and quality certifications already in place. Every truck that arrives meets the same specifications, carries the same documentation, and integrates with the company’s existing maintenance and tracking systems. If a safety recall occurs, the manufacturer knows exactly which components are in every vehicle because they built them all from the same baseline.
This analogy maps directly to how AMIs function in your AWS environment. A generic base AMI is like buying an empty truck chassis—you get the frame and engine, but you’re responsible for adding every other component yourself. Teams that build custom AMIs from generic bases often believe they’re creating exactly what they need, but they’re actually taking on the hidden work of specifying, testing, and documenting every hardening step and configuration choice. More importantly, they’re creating a unique artifact that only they fully understand.
A hardened AMI represents the next level of maturity. These images include security controls, system configurations, and compliance-relevant settings pre-applied according to recognized frameworks. A CIS-hardened AMI goes further by mapping those controls explicitly to Center for Internet Security benchmarks, providing a documented relationship between the technical implementation and the compliance requirement it satisfies.
The factory-standard AMI baseline takes this to the production-ready level by bundling the hardened image with an SBOM that catalogs every software component and its version, plus attestations that cryptographically verify the image hasn’t been tampered with since it was built. When you procure this baseline through AWS Marketplace, you’re not just getting a working image—you’re getting the evidence package that Security, Audit, and Compliance teams need to approve its use, packaged in a way that fits cleanly into enterprise procurement workflows.
The Hidden Cost of Hand-Rolled and Generic AMIs
The real expense of building and maintaining your own AMIs doesn’t appear in your AWS bill. It shows up as the accumulated hours your team spends on problems that shouldn’t exist in the first place. Configuration drift is the most insidious of these problems because it happens gradually and invisibly. An engineer makes a small change to improve performance on one instance. Another team member adds a monitoring agent to troubleshoot an issue. A third engineer updates a package to fix a bug but forgets to document the change. Six months later, no two instances in your fleet have exactly the same configuration, and nobody can definitively say which version represents the “correct” state.
This drift directly impacts your ability to respond to security threats. When a critical vulnerability requires immediate patching, teams spend hours just determining which systems are actually affected because package versions vary across the environment. Some instances were built from an AMI that’s three versions behind the current baseline. Others have manual modifications that were never committed back to the source image. The patch that works perfectly in one environment breaks services in another because the underlying configurations are different in ways that aren’t immediately obvious.
The audit and evidence problem compounds these technical challenges. Compliance frameworks require you to demonstrate that production systems meet specific security baselines, but that demonstration becomes nearly impossible when each instance represents a slightly different configuration. Teams end up generating evidence reactively—Security asks whether all production systems have a particular control enabled, and someone has to manually verify the configuration on every running instance because the AMI build process wasn’t documented thoroughly enough to answer the question with confidence.
Generic base AMIs seem like a reasonable middle ground, but they simply shift the burden rather than eliminating it. You still need someone to design the hardening approach, implement every security control, verify that nothing broke during the process, and document what was done well enough that future maintainers can understand and update the configuration. That person becomes a single point of failure for your infrastructure deployment process. When they leave or move to another team, the institutional knowledge about why certain configuration choices were made walks out the door with them.
Inside a Factory-Standard Baseline: What “Good” Looks Like
Hardened Defaults and Control Coverage
A production-ready baseline doesn’t just meet security requirements—it anticipates them. The hardening process applies controls systematically across multiple domains: access management, network security, logging and monitoring, and system configuration. Instead of treating each control as an isolated checklist item, the baseline implements them as an integrated security posture where controls reinforce each other.
Access management controls ensure that default accounts are disabled, password policies meet organizational requirements, and privilege escalation follows documented paths. Network security controls configure firewalls to deny by default, disable unnecessary services, and ensure that network traffic follows expected patterns. Logging and monitoring controls capture security-relevant events in standardized formats that integrate cleanly with your existing SIEM or log aggregation infrastructure. System configuration controls harden the kernel, apply filesystem restrictions, and ensure that the OS boots into a known-good state.
The critical difference between a hardened baseline and a manually hardened instance is consistency and verifiability. When every instance launches from the same baseline, you can make broad statements about your fleet’s security posture with confidence. More importantly, when you need to demonstrate compliance during an audit, the evidence exists at the image level rather than requiring instance-by-instance verification.
SBOM & Attestations as an Evidence Package from Day One
The Software Bill of Materials serves a function similar to a detailed parts list for complex machinery. According to NIST guidance, an SBOM is a formal record of the components and their relationships used in building a piece of software. It catalogs every software component in the image—the operating system packages, libraries, runtime environments, and utilities—along with their specific versions and dependencies. This granular inventory becomes essential when a vulnerability is disclosed because it allows you to instantly determine whether your baseline contains the affected component.
Attestations take this evidence a step further by providing cryptographic proof that the image you’re deploying is identical to the image that was tested and approved. When you launch an instance from an attested AMI, you can verify that nobody modified the image between the time it left the build pipeline and the moment it booted in your production environment. This verification chain closes a significant security gap that exists when teams build their own images without formal integrity checks.
The combined SBOM and attestation package fundamentally changes how you interact with Security and Audit stakeholders. Instead of responding to evidence requests after the fact, you can proactively share documentation that satisfies multiple compliance requirements simultaneously. When Audit asks whether production systems contain vulnerable versions of a particular library, the SBOM provides a definitive answer. When Security needs to verify that an image meets hardening requirements, the attestation proves that the running instance matches the approved baseline.
Patch Cadence & Image Propagation Instead of Instance-by-Instance Patching
Traditional patching treats each running instance as the unit of work. When a security update is released, teams deploy the patch to every instance individually, either through configuration management tools or by manually executing commands. This approach creates several problems. First, it requires that instances remain running during the patch process, which means you’re modifying production systems in place rather than replacing them with known-good configurations. Second, it introduces timing and state management complexity—some instances will be patched before others, creating temporary inconsistency across the fleet.
Image-based patch cadence inverts this model. Instead of patching running instances, you update the baseline AMI, test the new image thoroughly in a non-production environment, and then replace instances by launching new ones from the updated AMI. This approach treats instances as disposable artifacts that can be terminated and recreated at will, which aligns naturally with modern cloud architecture patterns.
The operational benefits are substantial. When you need to roll back a problematic update, you simply launch new instances from the previous AMI version rather than trying to reverse individual patches on running systems. When you need to scale your fleet, new instances automatically incorporate the latest patches because they launch from the current baseline. When disaster recovery requires rebuilding infrastructure from scratch, the recovery process uses the same AMI you use for normal operations, eliminating the risk that DR environments diverge from production over time.
This pattern also provides controlled blast radius during updates. You can deploy the updated AMI to a small percentage of your fleet first, monitor for issues, and gradually expand the rollout if everything behaves as expected. If problems surface, you can halt the propagation immediately without affecting instances that are still running the previous version. This level of control is difficult to achieve when patching instances in place because there’s no clean separation between the old and new states.
Adopting AMI on AWS via AWS Marketplace Without Breaking Velocity
Evaluating Factory-Standard AMIs
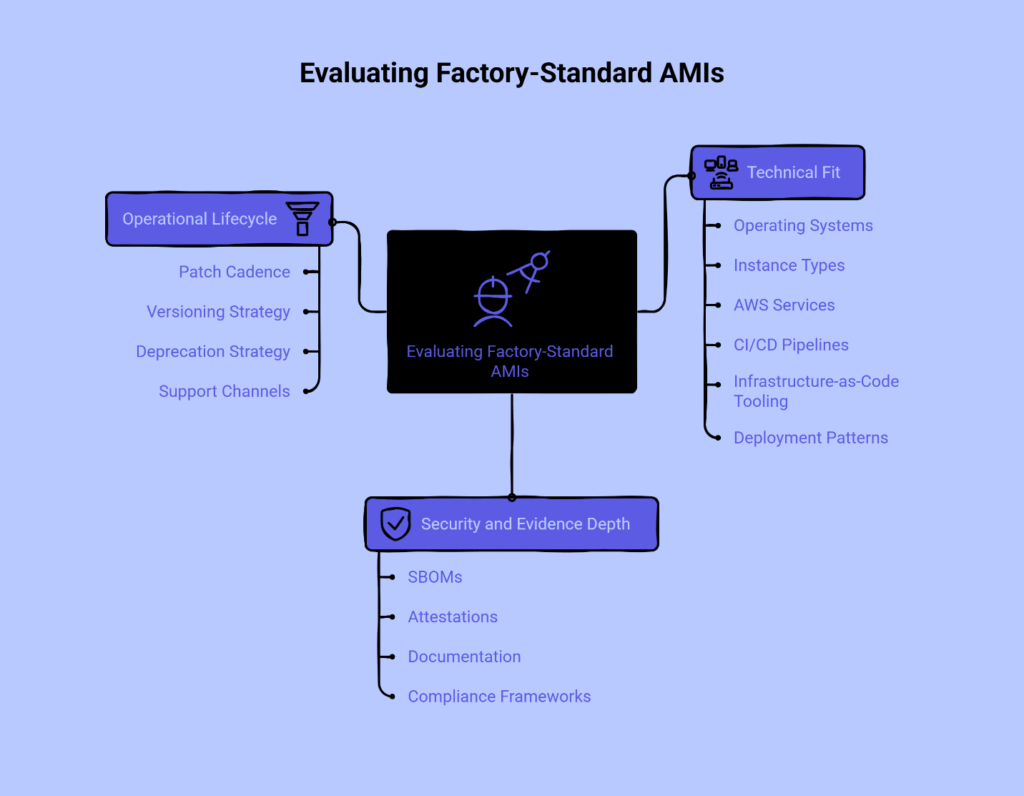
The evaluation process for a baseline AMI should focus on three key areas that determine both technical viability and organizational fit.
Technical fit means verifying that the baseline supports the operating systems, instance types, and AWS services your team actually uses. A baseline that only supports older OS versions or lacks compatibility with the instance families you’re standardizing on creates more problems than it solves. Consider whether the image works cleanly with your existing CI/CD pipelines, whether you’re using AWS CodePipeline, Jenkins, GitLab, or another platform. Verify that it supports your infrastructure-as-code tooling, whether that’s CloudFormation, Terraform, or AWS CDK. Most importantly, confirm it fits into your deployment patterns—if your team uses Auto Scaling groups, the baseline needs to work as a launch template source; if you’re using containerized workloads on EC2, the baseline should serve as a stable host OS for your container runtime.
Security and evidence depth determines how easily you can satisfy your organization’s compliance and security requirements. Look for baselines that include comprehensive SBOMs, attestations from recognized build systems, and clear documentation of which controls are implemented. The evidence should be machine-readable where possible so you can automate compliance checking rather than relying on manual reviews. For organizations that need to show alignment with specific frameworks, verify whether the baseline maps to CIS Benchmarks or other relevant control sets.
Operational lifecycle considerations are often overlooked during evaluation but become critical during adoption. Understand the stated patch cadence—whether the provider commits to monthly updates plus out-of-band releases for critical CVEs. Review the versioning and deprecation strategy to know how long old versions remain available and how they’re marked as end-of-life. Confirm the availability of support channels for clarifying hardening decisions or troubleshooting roll-out strategies.
Consider running a limited trial where you deploy the baseline AMI in a non-production environment and execute your standard deployment workflows against it. This trial should include launching instances, applying any additional configuration through your existing automation, running your test suites, and verifying that monitoring and logging work as expected. The goal is to identify integration friction points before you commit to using the baseline across your entire infrastructure.
Using AWS Marketplace and Private Offers to Cut Procurement Delays
AWS Marketplace procurement provides a significant advantage over traditional software purchasing: it consolidates billing through your existing AWS account rather than requiring separate contracts, purchase orders, and payment workflows. This consolidation matters because it eliminates several approval steps that typically delay technology purchases in enterprise environments. Instead of routing a request through Procurement, Legal, and Finance for contract review and payment setup, you can often complete the acquisition using delegated authority within your AWS organization.
AWS Marketplace private offers take this efficiency further by allowing you to negotiate custom terms directly with the provider while still using the streamlined Marketplace procurement mechanism. This is particularly valuable when you need to address specific compliance requirements, adjust pricing based on committed usage volumes, or include custom support terms that go beyond the standard offering. The private offer becomes a single agreement that addresses both the technical and commercial aspects of the baseline adoption, reducing the back-and-forth that typically occurs when you’re coordinating multiple separate agreements.
For teams operating under procurement policies that require competitive evaluation or formal approval processes, the Marketplace listing itself can serve as part of the evidence package you need to present to stakeholders. The listing includes detailed product descriptions, pricing information, customer reviews, and security documentation that addresses common questions before they’re asked. This transparency accelerates the approval process because stakeholders can review the offering on their own schedule rather than waiting for sales meetings or proposal submissions.
Rolling Out the Baseline Across Accounts and Regions
Multi-account, multi-region distribution of a baseline AMI follows patterns that mirror how enterprises distribute other shared resources like service catalogs or approved tool sets. The most direct approach is to share the AMI from a central account to all accounts in your AWS organization, creating AMI copies in each region where you operate. This creates region-local resources that your deployment automation can reference without cross-region dependencies.
For organizations that need tighter control over AMI distribution, you can implement a hub-and-spoke model where a central infrastructure team maintains the baseline, tests updates in a dedicated validation environment, and explicitly approves new versions for distribution. Accounts that consume the baseline reference approved AMI IDs through a central registry or parameter store, ensuring that teams can’t accidentally deploy unapproved images.
The rollout process itself should be gradual and observable. Begin with development and test environments where the impact of any integration issues is minimal and the feedback cycle is fast. Use these environments to verify that your deployment automation works correctly with the new baseline, that application dependencies are satisfied, and that performance meets expectations. Once you’ve confirmed that the baseline works in lower environments, expand to a small subset of production instances—perhaps a single availability zone or a canary deployment that represents a small percentage of production traffic.
Monitor key metrics throughout the rollout: instance launch success rates, application startup times, error rates in your application logs, and any security tool alerts that might indicate unexpected behavior. Establish clear rollback criteria before you begin so that everyone understands the conditions under which you’d revert to the previous baseline. This disciplined approach to rollout prevents the common pattern where teams adopt new infrastructure hastily and then spend weeks troubleshooting issues that could have been caught with a more measured deployment.
For detailed implementation guidance specific to your infrastructure automation tools and deployment patterns, the deployment documentation provides step-by-step procedures and example code that you can adapt to your environment.
Exploring Key Topics for Deeper Understanding
This article establishes the foundational concepts and benefits of a factory-standard AMI baseline. Several specialized areas warrant deeper exploration as your organization matures its AMI management practices.
Zero-day vulnerability response represents one of the most critical operational scenarios where a standardized baseline demonstrates its value. Organizations using image-based patch cadence can build, test, and propagate updated baseline images through controlled rollout patterns, managing the release process without creating production chaos. Teams currently handling zero-days through emergency manual patching sessions may find particular value in exploring systematic approaches to vulnerability response that leverage AMI baselines as the primary control point.
Compliance framework alignment becomes significantly more efficient when baseline images explicitly document their relationship to recognized control sets such as CIS Benchmarks. Control-mapped base images provide the bridge between technical implementation and the compliance evidence that auditors need to review, particularly during audits when demonstrating that infrastructure meets specific regulatory requirements.
Procurement optimization addresses a common bottleneck in infrastructure modernization. Understanding how to leverage private offers and standard Marketplace terms can shorten approval cycles considerably. This topic covers common questions from Procurement and Legal teams, internal approval request patterns, and how Marketplace billing consolidation simplifies the commercial relationship with infrastructure software providers.
Lifecycle management for golden AMIs requires sustainable practices around ownership models, versioning strategies, update cadence decisions, and deprecation policies. Platform teams responsible for maintaining baseline images over time benefit from established patterns that prevent the baseline from becoming yet another piece of infrastructure that nobody wants to touch because the original maintainers have moved on.
Control-level implementation details provide granular documentation about which specific security controls are implemented, how they’re configured, and what evidence exists to verify their presence. This depth becomes essential for security architects and compliance specialists who need to trace from organizational policy to baseline implementation.
If you’re dealing with the broader challenge of improving how your teams coordinate during incidents, the existing resource on rapid incident resolution provides a first-hour playbook that cuts mean time to resolution without requiring additional headcount. Similarly, if you’re working to eliminate hand-off failures between teams, the guide on implementation and systems integration offers a framework designed specifically for mid-market operations teams.
From Firefighting to Predictable Releases: Where This Baseline Takes You Next
The transformation from ad-hoc image management to a standardized baseline approach delivers immediate tactical benefits—faster security responses, easier audit preparation, and more consistent deployments. But the strategic value emerges over time as the baseline becomes the foundation for broader infrastructure improvements.
When your entire fleet launches from a known-good baseline, you can start making confident assertions about your security posture that were previously impossible. You can tell stakeholders with certainty that no production system contains a particular vulnerable package because the SBOM proves its absence. You can implement security controls at the image level with confidence that they’ll be present on every instance that launches, eliminating the “Was this control applied?” questions that currently consume time during audits.
The baseline also enables operational patterns that require infrastructure homogeneity. Auto-scaling becomes more reliable when you know that every instance that joins the fleet has an identical configuration. Disaster recovery becomes faster because rebuilding infrastructure means launching instances from the same AMI you use every day, not trying to recreate custom configurations from documentation that may be outdated. Blue-green deployments and canary releases become viable strategies because you can trust that instances behave consistently regardless of when or where they were launched.
As your organization matures its cloud practices, you’ll likely expand the baseline concept to include additional standardization: application runtime environments, monitoring agents, security tools, and operational utilities. The factory-standard AMI becomes the platform on which your entire application delivery process builds. Teams stop asking “How should I configure this?” and start asking “How does our baseline handle this?” That shift in thinking represents the difference between infrastructure as a collection of individually maintained servers and infrastructure as a managed platform with predictable characteristics.
The path forward involves extending the baseline approach to other aspects of your infrastructure. Consider how the same evidence-based, standardized model could apply to container images, Lambda function deployment packages, or database configurations. The underlying principle remains the same: reduce variance, increase automation, and package evidence alongside the artifacts you deploy.
Explore our guides on AMIs, SBOMs, and zero-day response to see how factory-standard baselines integrate with your existing workflows.
References
[1] Amazon Web Services. “Amazon Machine Images (AMI).” AWS Documentation. https://docs.amazonaws.cn/en_us/AWSEC2/latest/UserGuide/AMIs.html
[2] National Institute of Standards and Technology (NIST). “Software Bill of Materials (SBOM).” NIST Computer Security Resource Center. https://csrc.nist.gov/glossary/term/software_bill_of_materials
[3] Amazon Web Services. “Private Offers – Frequently Asked Questions.” AWS Marketplace Documentation. https://docs.aws.amazon.com/marketplace/latest/userguide/private-offer-faq.html
Disclaimer
The information in this guide is for general informational purposes only and does not constitute legal, security, or compliance advice.
Our Editorial Process
Our expert team uses AI tools to help organize and structure our content, and every piece is reviewed by subject-matter-informed humans on our Insights Team to ensure accuracy and clarity.
About the Gigabits Cloud Insights Team
The Gigabits Cloud Insights Team is our dedicated engine for synthesizing complex topics into clear, helpful guides. While our content is thoroughly reviewed for clarity and accuracy, it is for informational purposes and should not replace professional advice.






