
📌 Key Takeaways
When a zero-day CVE drops hours before a scheduled release, hand-rolled AMIs and ad-hoc patching turn a single vulnerability into multi-day chaos for small cloud teams.
- Factory-Standard Baselines Shrink the Blast Radius: CIS-hardened AMIs with SBOM attestations let teams patch one vetted image instead of scrambling across N snowflake instances, cutting both technical risk and cognitive load.
- A Seven-Stage Response Flow Replaces Panic with Process: Detect, assess, update, validate, promote, decide, and capture evidence—this documented playbook transforms zero-day response from improvised heroics into a repeatable operational drill.
- Regular Cadence Beats Reactive Firefighting: Monthly AMI refresh cycles aligned with known patch windows shift vulnerability management from late-night emergencies to planned daytime work, protecting both system reliability and team morale.
- Clear Rollback Criteria Prevent Cascading Outages: Pre-recorded AMI IDs and documented decision points eliminate hesitation during production rollouts, letting small teams execute confidently without enterprise-scale resources.
- Parameter Stores and Pipeline Guardrails Lock In Consistency: When CI/CD pipelines reference “latest approved AMI ID” from configuration stores and block unknown images, drift stays out and standardization stays in.
Prepared baselines mean faster response and steadier releases. Cloud operations managers, DevOps engineers, and infrastructure teams at small U.S. businesses running production workloads on AWS will find the operational framework here, preparing them for the detailed implementation guidance that follows.
The notification arrives at 3 PM on a Thursday. A critical CVE just dropped. Your security scanning tools light up across the EC2 fleet. Tomorrow’s release—the one leadership has been tracking for weeks—just became a question mark.
For cloud teams at small businesses running production workloads on AWS, this scenario hits differently than it does at large enterprises. You don’t have a dedicated security team to handle the triage. The same engineers who built the deployment pipeline are now scrambling to assess exposure, patch systems, and somehow maintain the release schedule. When your AMIs were hand-rolled months ago with slightly different configurations across dev, staging, and production, a zero-day doesn’t just create technical debt. It creates chaos.
The alternative exists today. AMI on AWS built on CIS-hardened baselines transforms zero-day response from an improvised fire drill into a documented, repeatable process. An AMI on AWS is a pre-built Amazon Machine Image designed for secure, compliant, repeatable deployment on AWS. Think of it as a manufacturer-approved factory baseline for your fleet. Teams experience smoother deploys that pass security checks without last-minute rework.
This article walks through exactly how small teams respond to zero-days using hardened AMI baselines—from initial detection through controlled propagation across environments, with clear rollback criteria and audit evidence built in.
When a zero-day hits, image drift turns into release chaos for small teams
The typical small-team response to a critical vulnerability follows a predictable pattern. Someone SSHes into production servers and applies patches where the exposure seems highest. Another engineer updates staging instances using a slightly different process. Dev environments might get patched days later, or not at all if the sprint is tight.
Each environment becomes a snowflake. No single source of truth exists for what’s actually running where. When the security lead asks, “Which specific package versions are deployed in production right now?” the answer requires SSH sessions, manual checks, and educated guesses. Auditors find this lack of consistency troubling. Leadership finds it risky.
Image drift amplifies every zero-day response challenge for teams already operating at capacity. The same people who need to patch systems are also on-call for incidents and responsible for shipping features. Every unplanned fire drill steals hours from planned work. Rollback decisions become nerve-wracking because reverting to “the previous state” means reverting to a configuration that wasn’t clearly documented in the first place.
According to CISA’s Known Exploited Vulnerabilities Catalog, organizations face an ongoing stream of critical vulnerabilities requiring rapid response. Small teams can’t afford to treat each one as a unique emergency requiring custom solutions.
Use hardened AMI baselines to shrink the zero-day change set
A CIS-hardened AMI provides security best practices baked into the image itself. Instead of maintaining dozens of slightly different server configurations, you maintain one vetted baseline. When a zero-day drops, you patch that single baseline AMI rather than scrambling across N snowflake instances.
The Software Bill of Materials (SBOM) and basic attestations that come with a properly maintained hardened AMI answer the audit question before it’s asked. You can demonstrate exactly what changed between image version 1.2.4 and 1.2.5. The evidence trail exists by design, not as an afterthought assembled during a compliance review.
Here’s what changes operationally. Pre-hardened baselines reduce the change set during zero-day response. You’re not patching the operating system, reconfiguring security groups, adjusting firewall rules, and updating monitoring agents simultaneously. You’re updating a known good baseline and propagating that tested change forward. This approach cuts both the technical risk and the cognitive load on small teams.
The AWS Well-Architected Framework explicitly encourages standardizing on golden images and automating patch management to keep fleets consistent and recoverable. This architectural guidance aligns directly with the operational reality small teams face: reducing variance across environments makes incident response faster and more predictable.
Gigabits Cloud’s AMI on AWS delivers CIS-aligned baselines designed specifically for teams that need production-ready infrastructure without months of custom hardening work. Available through AWS Marketplace, these images integrate into existing EC2 and pipeline setups rather than forcing a complete re-architecture. You can trial an AMI in a test account, review the hardening documentation, and integrate it into your workflows on your timeline.
The relationship to other tools in your stack matters. AMI-based updates sit alongside, not in place of, OS-level package management and configuration management tools like Ansible or AWS Systems Manager. Think of the hardened AMI as your starting line—the baseline you build on, not the only tool you use. For ongoing configuration drift detection and routine updates, you’ll still use your existing automation. The AMI gives you a clean, auditable foundation to start from.
Design a calm, repeatable Zero-Day AMI Response Flow
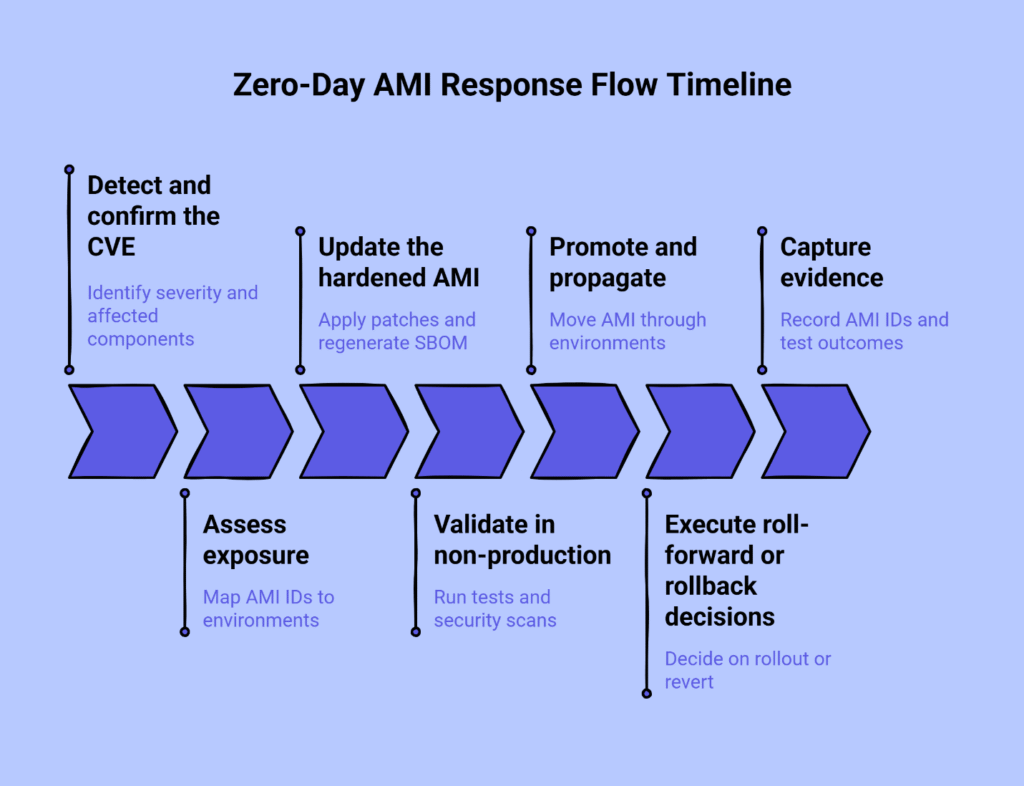
A documented response flow transforms panic into process. The following seven stages form the core of zero-day response using hardened AMI baselines.
Stage 1: Detect and confirm the CVE
Identify the severity rating and affected components. Confirm which operating system versions, runtime environments, or dependencies are impacted. This is straightforward fact-gathering from vendor advisories and security bulletins, typically from sources like the National Vulnerability Database, which treats a CVE as a standardized identifier for specific vulnerabilities, helping teams quickly correlate issues with installed components.
Stage 2: Assess exposure
Determine which of your hardened AMIs contain the vulnerable components. Map specific AMI IDs to each environment—dev, staging, production, and any others you maintain. This step requires knowing exactly what’s running where, which is why image-based infrastructure provides an advantage over configuration drift across individual instances.
Stage 3: Update the hardened AMI
Apply the vendor patches and any required configuration changes to your CIS-hardened baseline. Regenerate the SBOM to reflect the new package versions. This concentrated work happens once, on one image, rather than scattered across multiple environments. Most teams integrate this step with existing automation—image builders, configuration management tools, or AWS Systems Manager Documents—so the patched AMI is produced via repeatable code rather than manual intervention.
Stage 4: Validate in non-production
Run your standard test suite against the updated AMI in a non-production environment. Include smoke tests, integration checks, and performance verification. Add targeted security scanning focused on the components you just patched. The goal is confirmation that the patch doesn’t introduce new issues.
Stage 5: Promote and propagate
Move the validated AMI through your environments using pre-defined promotion criteria. Those criteria typically include test passage, documented rollback procedures, and approval from your designated incident commander or cloud operations lead. Propagating an updated AMI through environments is safer than ad-hoc patching across snowflake instances because you’re moving a tested, known state forward.
Stage 6: Execute roll-forward or rollback decisions
Establish clear decision points before you begin. Under what conditions do you continue the rollout to the next environment? When do you revert to the last known good AMI? Having previous AMI IDs recorded and rollback procedures documented eliminates hesitation during execution. Clear roll-forward and rollback criteria prevent cascading outages and reduce stress for small teams.
Stage 7: Capture evidence
Record the AMI IDs, creation timestamps, environment promotion times, test outcomes, and links to the relevant security advisories. This evidence supports both operational retrospectives and audit requirements. The format matters less than the habit of consistent capture.
Many teams screenshot this flow or export it to PDF for inclusion in runbooks and incident response documentation. The value isn’t just in having the process written down—it’s in having practiced it before the next critical CVE arrives.
Patch cadence and image propagation without burning out a 1–50 person team
Moving from reactive, panic-driven patching to a defined cadence changes both the technical outcomes and the human experience of infrastructure work.
Regular hardened AMI refresh cycles—monthly or aligned with Patch Tuesday equivalents for your specific stack—shift vulnerability management from late-night emergencies to planned daytime work. Security agencies have repeatedly noted that many exploited vulnerabilities are older, known issues rather than brand-new zero-days. A regular cadence helps close that gap for small teams that cannot chase every advisory in real time.
When your pipelines always reference the latest approved hardened AMI ID—stored in a parameter store or configuration management system—new instance launches automatically use the current, vetted baseline. Guardrails that catch unknown or unapproved AMI IDs prevent configuration drift from creeping back in.
Integrating this cadence into CI/CD pipelines doesn’t require exotic tooling. Most teams already have the necessary automation in place. The change is conceptual: treating the AMI ID as a versioned, controlled artifact rather than a forgotten detail of infrastructure setup.
For teams concerned about maintaining velocity during incidents, the approach detailed in Rapid Incident Resolution: The First-Hour Playbook That Cuts MTTR Without Adding Headcount complements AMI-based response. Both emphasize clear command structures, blast radius control, and documented decision-making under pressure.
The human element deserves direct acknowledgment. Reducing pager noise and creating more predictable change windows improves team sustainability. A 1–50 person infrastructure team cannot afford to burn engineers on repetitive fire drills. Moving zero-day response toward a routine play rather than a hero event protects both system reliability and team morale.
As teams mature their AMI lifecycle practices, the natural next step involves full automation of the bake, verify, and distribute cycle. That progression—from manual response to automated propagation with drift controls—represents the future state for teams committed to sustainable infrastructure operations.
What Gigabits Cloud’s AMI on AWS changes for your next zero-day
The contrast between approaches becomes clearest during an actual incident.
Without hardened AMI baselines, you face hand-rolled images with unknown drift, ad-hoc patching scattered across environments, and fuzzy rollback options. The audit trail gets assembled after the fact, if at all. Questions from leadership about exposure and remediation status require investigation rather than instant answers.
With Gigabits Cloud’s AMI on AWS, you start from a CIS-aligned baseline you can rely on. The Zero-Day AMI Response Flow becomes your documented, practiced procedure centered on controlled image updates rather than improvised fixes. The entire evaluation and procurement path runs through online channels—trial the AMI in a test account, validate it against your requirements, integrate it into your pipelines, and purchase through AWS Marketplace when ready.
This online-first model matches how small technical teams actually work. You don’t need to schedule sales calls or wait for quotes. The AMI is available for evaluation immediately. Documentation, hardening specifications, and support resources are accessible through standard web interfaces.
Browse EC2 AMI listings to see available hardened baselines for your stack, or launch your AMI in 1-Click on AWS Marketplace to begin testing in your environment today.
Prepare once, respond calmly to the next zero-day
You’re not rebuilding the engine mid-flight when you use factory-standard baselines. You’re swapping in a tested, standardized component with known characteristics and documented changes.
The transformation from ad-hoc patching to a documented, shareable response play benefits small teams specifically because it eliminates wasted effort and reduces surprises. Fewer blocked releases. More predictable conversations with leadership about risk. Clearer answers when auditors ask about your security posture and incident response capabilities.
Zero-days will continue arriving. The question isn’t whether your team will face critical vulnerabilities—it’s whether you’ll face them with a rehearsed plan or another improvised scramble. Hardened AMI baselines turn that rehearsed plan into standard practice.
For teams ready to build more comprehensive operational maturity across system boundaries and hand-offs, the implementation framework detailed in From Hand-Off Failures to One Flow: An Implementation & Systems Integration Framework for Mid-Market Ops extends these principles beyond just infrastructure response into broader process design.
The groundwork you lay today with standardized AMI baselines directly enables tomorrow’s fully automated golden AMI lifecycle—where baking, verification, and distribution happen with drift controls and continuous validation built in. That’s the path forward for infrastructure teams that ship reliably without burning out.
Disclaimer
The guidance in this article is based on common patterns observed in cloud infrastructure and security operations. It is provided for informational purposes only and does not constitute legal, security, or compliance advice. Always validate architecture and controls against your organization’s policies, regulatory obligations, and current vendor documentation.
Our Editorial Process
Every piece from the Gigabits Cloud Insights Team is grounded in practice, informed by real-world customer scenarios, internal runbooks, and AWS best practices. Content is technically reviewed by cloud infrastructure and security specialists before publication and kept current as AWS services, security guidance, or Marketplace capabilities materially change. Where we reference third-party standards or documentation, we link to the most authoritative, up-to-date sources available at the time of writing.
Gigabits Cloud Insights Team
focuses on practical, implementation-driven guides for cloud operations, security, and platform engineering. We specialize in helping small and growing teams ship faster on AWS using hardened, production-ready AMIs that balance delivery speed with compliance and auditability.






